Raffel, Colin. “Learning-Based Methods for Comparing Sequences, with Applications to Audio-to-MIDI Alignment and Matching”. PhD Dissertation. Columbia University. 2016.”** This PhD thesis presents learning-based methods for comparing sequences in order to facilitate large-scale sequence search. The author focusses on the problem of matching MIDI files to a large collection of audio recordings of music.
Dynamic time warping (DTW) is used for aligning and matching sequences. I’ve come across Query by Singing/Humming systems that are based on that. In one part of the thesis, the author uses Bayesian optimization to tune system design and parameters over a synthetically-created dataset of audio and MIDI pairs. This kind of parameter tuning is a new unknown for me.
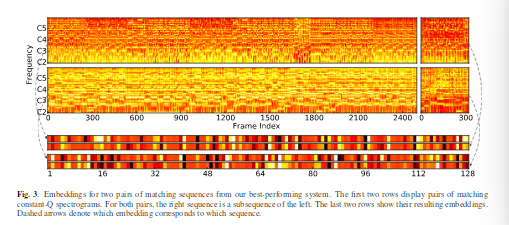
In another part of the thesis, he studies mapping sequences of continuously-valued feature vectors to downsamples sequences of binary vectors. His approach involves training a pair of convolutional networks to map paired groups of subsequent feature vectors to a Hamming space where similarity is preserved.
In the next part, he avoids DTW entirely by mapping the whole sequence to a fixed-length vector in an embedded space where sequence similarity is approximated by Euclidean distance. To achieve this embedding, he uses a very interesting architecture. A feed-forward attention-based neural network model which can integrate arbitrarily long sequences.
The idea of embeddings is indeed “very attractive”. I don’t yet understand the attention mechanism entirely. It seems to me like a obtaining a weighted average that takes as inputs all embeddings produced (one embedding must be produced for every spectrogram image). I’ll study this further and update this post.