DeepLog: Anomaly Detection and Diagnosis of System Logs through Deep Learning. Min Du, Feifei Li, G. Zheng, V. Srikumar. ACM CCS 2017.
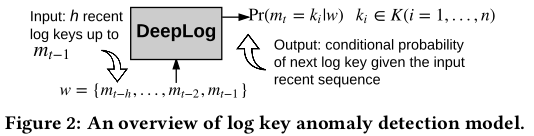
DeepLog is a system that performs anomaly detection and diagnosis from system logs through deep learning. It utlizes a recurrent neural network called Long Short Term Memory (LSTM) to model the system log as a natural language sequence. DeepLog detects anomalies when log patterns deviate from the model trained from log data under normal execution.
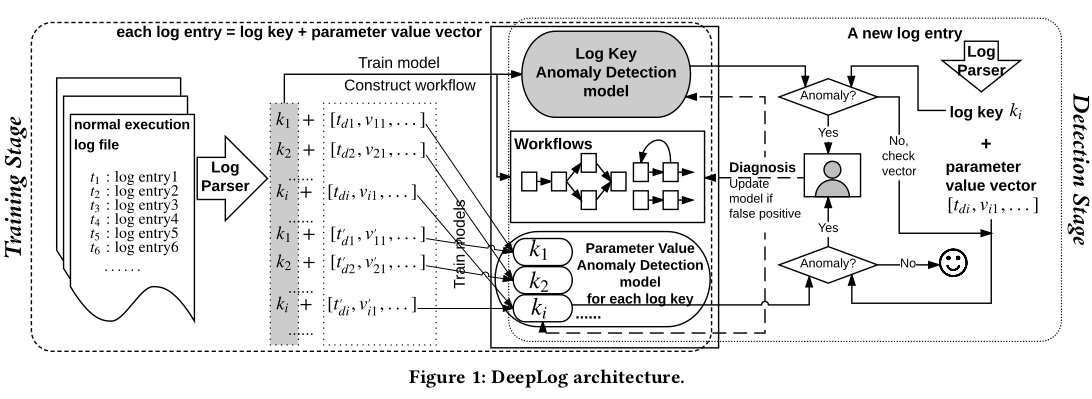
The Spell log parser is used to obtain two structured datasets from the syslog (figure below): a sequence of log keys (message types) and a sequence of parameter value vectors. Spell is an online streaming parser that utilizes a longest common subsequence based approach. The time complexity to process each log entry e is close to linear (to the size of e). I’ve only taken a cursory look at the Spell paper and need to study it more carefully to understand how the parsing happens.

Anomaly detection is performed at two levels:
-
A log key anomaly detection LSTM model predicts the next log message type (log key). If it is wrong for any log entry, the operator is alerted that there is an anomaly in the execution flow.
-
If there is no anomaly in the execution flow, the parameter value and performance anomaly detection model is invoked. If the predicted parameter vector for that particular log key is very different from the actual parameter vector, the operator is alerted. The second model performs regression, in high-dimension space of the parameter feature vector. Therefore, the mean-squared error (MSE) is used as the loss function when training this model and when deciding to alert the operator.
The exact architecture of DeepLog is shown below:
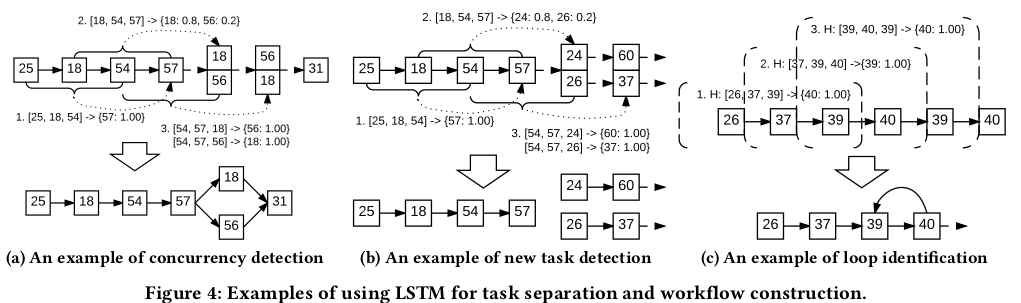
The paper also focusses on “Workflow Construction from Multi-Task Execution” (Section 4) for aiding in anomaly diagnosis. They propose two ways of going about this: using the execution path anomaly LSTM model and density-based clustering. When leveraging the LSTM model, they describe how shared segments, concurrency, new tasks, if-then branches and loops can be identified from the LSTM output probabilities. I believe that these are instructions that have to be translated into code that generates workflows from LSTM outputs. example of anomaly diagnosis using constructed workflow is shown below:
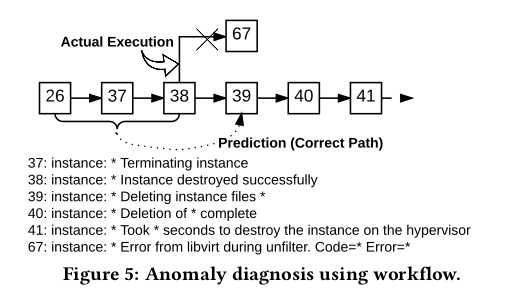
The figure below shows how the workflow can be used for anomaly diagnosis.
The authors have created a section that points to related work in the area: unsupervised methods like PCA (SOSP 2009) and Invariant Mining, a TFIDF binary LSTM classifier for IT system failure prediction and the CloudSeer workflow anomaly detection method.
Evaluation
First off, the authors have been very transparent about how to obtain and use the datasets they evaluated their system on. The system was evaluated on two datasets that are : HDFS log data set from the SOSP 2009 paper and the OpenStack log data set. Only 1% of the HDFS dataset was used for training.
For parameter value and performance anomaly detection, syslogs from OpenStack VM creation task were used. To simulate a performance anomaly which could be caused by a DoS attack, network speed from the controller to the compute nodes was throttled at two different points. These anomalies were successfully detected.
The authors also investigate systems containing real attacks to demonstrate DeepLog’s effectiveness. They use the VAST Challenge 2011 network security logs (firewall and intrusion detection system) where DeepLog performs well: only one false positive and one false negative. DeepLog also detects atypical messages produced in kernel log by Blind Return Oriented Programming (BROP) attacks.
The paper contains details about online training and system performance that I won’t go into detail here. For example, DeepLog’s prediction cost per log entry is only around 1 millisecond on a standard non-GPU workstation (deep learning algorithms obtain an order-of-magnitude improvement in performance on GPUs).
Here are the default values for hyperparameters (configurations that the system doesn’t learn from data):
- cutoff in the prediction output to be considered normal, g = 9. g can be adjusted to achieve higher true positive rate or lower false positive rate.
- window size used for training and prediction, h = 10.
- number of layers in the LSTM network, L = 2.
- number of memory units in one LSTM block, alpha = 64.